Beginning Data Analysis And Data Science

Data science as a concept and practice has many definitions. Some definitions out there are: ‘ Data Science is the sexiest field of study and or career’. ‘ Data Science is a Multidisciplinary study anchored on domain knowledge’. ‘ Data Science is an intersection of Statistics, Computer Science, Mathematics, Software Development and Domain expertise’. e.t.c . You would agree that Data Science is an exceptionally diverse and exciting field which marries both worlds of art and sciences. My favourite definition is that which considers Data Science as a Multidisciplinary study because, in my opinion, Data Science is not an end of itself but a means to an end! On that note, I welcome you, yes, you reader- to this week’s post which promises to be exciting and educative.
In the preceding lines, I surmised that Data Science is a means to an end and not the other way round because, from my experience, its application transcends many filed of study and careers. To this end, any domain expert or domain newbie can apply the power of data science to solve problems unique to that domain. As much as I acknowledge these characteristics as plausible, there are some drawbacks and shortcomings. However, the most glaring one is the tendency to attract individuals with little or no foundation in Statistics, Mathematics and coding skills. My attention is on such category of persons because I believe with some structure anybody irrespective of their knowledge of Statistics, Mathematics or python skills can apply and unleash the powers of data science. Consequently, the focus of this post is on the initial steps that you observed as you decide to solve a Data Science problem. I classify these steps into two broad parts:
- Pre Data steps
- Data steps
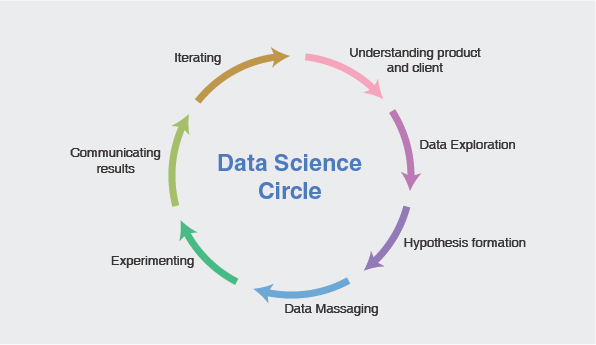
Pre-Data Steps
While this step is the most crucial in the data science circle, it is equally the most overlooked or neglected. A typical data science circle may involve:
- Understanding product snd client
- Data Exploration
- Hypothesis formation
- Data Massaging
- Experimenting
- Communicating results
- and Iterating
From the above steps, not for nothing does a pre-data step- Underderstanding product and clients- comes first. It’s a critical step that formed the foundation of other steps. Understanding product and clients mean being abreast with the goals and objective of the problem. To cover this step sufficiently, you may ponder and answer the following questions:
- why is this problem important? as they say there is a story behind a story This may involve carrying out a need analysis from the perspective of the client or the owner of the data
- Is there enough data?
- How can performance be measured or the Key Performance Indicator
- Will the solution be descriptive and or prescriptive?
- Does the problem require data science or machine learning?
- what tools or environment available or affordable
- e.t.c
Of course, this list is by no means exhaustive. The more questions, the more profound will your understanding of the clients and products.

Data Steps
Under this phase, the probing moves from theoretical to more technical.
- Meta Data
- Data preprocessing
Meta Data is simply data about data, and the following process can be used under a jupyter/pandas environment to understand the metadata of our data set.
Load the data unto jupyter using the appropriate pandas’ method to read your data accordingly. Assuming the data is in CSV format, we would read and saved it to a variable
import pandas as pd
import numpy as np
data_read = pd.read_csv('path to data on local machine or external url')`
data_read.shape
#get the numbers of columns and rows of data
data_read.info()
# displays detailed info about the data set`
data_read.dtypes # displays the various data types of the variables in of the data sexiest
data_read.describe(include=[np.number]).T # Get the summary Statistics for the numerical variable and transpose the DataFrame
data_read.describe(include =[np.object, pd.Categorical]).T # Get the summary Statistics for the object and Categorical columns
data_read.memory_usage(deep=True)
# display the space occupied by the various data variables and types
Data preprocessing include any and every data acrobatics deemed necessary to shape the required data for further analysis or machine learning. However, the entire Data steps can be subsumed under data exploration, as noted under the data science life circle.
The field of data science is a growing field of study and career. Because of this dynamism, processes and procedures changes by the speed of light, and the best attitude is to have an open mind and be ready to learn to unlearn and re-learn. And talking about education, I hope you have learned something, however small from this post. Bye!